RAG Chunking Strategies: What’s the Optimal Chunk Size?

Published on

A deep dive into text chunking for Retrieval-Augmented Generation systems
Introduction: Why Chunking Matters in RAG
Retrieval-Augmented Generation (RAG) has become the go-to pattern for building LLM applications that need access to external knowledge. The concept is elegantly simple: instead of fine-tuning a model on your data, you retrieve relevant context at query time and inject it into your prompt.
But here’s the thing most tutorials gloss over: the quality of your RAG system lives or dies by how you chunk your documents.
Chunking-the process of splitting documents into smaller pieces for embedding and retrieval-sits at the critical junction between your raw data and your vector store. Get it wrong, and you’ll either retrieve fragments too small to be useful or chunks so large they bury the relevant information in noise.
Consider this scenario: A user asks ,“What’s the refund policy for enterprise customers?” Your document contains the answer, but it’s embedded in a 50-page terms of service. How you chunk that document determines whether you retrieve:
- A useless fragment: “…enterprise customers are entitled to…”
- An overwhelming wall of text containing 15 different policies
- A perfectly-scoped chunk with exactly the refund policy details
This post explores the major chunking strategies, their tradeoffs, and provides working code with benchmarks to help you make informed decisions for your use case.
Chunking Strategies: The Four Horsemen
1. Fixed-Size Chunking
The simplest approach: split text into chunks of exactly N characters (or tokens), with optional overlap.
How it works:
Document:"The quick brown fox jumps over the lazy dog. It was a sunny day."Chunk size:30chars,Overlap:10Chunk 1: "The quick brown fox jumps over"Chunk 2: "jumps over the lazy dog. It wa"Chunk 3: "dog. It was a sunny day."
Pros:
- Predictable chunk sizes (great for token budget management)
- Fast and simple to implement
- Consistent embedding dimensions
Cons:
- Cuts mid-sentence, mid-word, even mid-concept
- No respect for document structure
- Overlap helps but doesn’t solve semantic fragmentation
Best for: Uniform text without strong structure (logs, transcripts, simple prose)
2. Recursive Character Splitting
LangChain’s default approach. Attempts to split on natural boundaries in order of preference: paragraphs → sentences → words → characters.
How it works:
- Try to split on \n\n (paragraphs)
- If chunks still too large, split on \n (lines)
- Then on . (sentences)
- Then on (words)
- Finally, on individual characters
Pros:
- Respects document structure where possible
- More semantically coherent chunks
- Configurable separator hierarchy
Cons:
- Chunk sizes vary significantly
- Can still produce awkward splits
- Doesn’t understand actual semantic meaning
Best for: General-purpose documents, articles, documentation
3. Sentence-Based Chunking
Splits text at sentence boundaries, then groups sentences until reaching a size threshold.
How it works:
- Parse document into sentences using NLP (spaCy, NLTK, or regex)
- Group consecutive sentences until chunk size limit
- Optionally overlap by N sentences
Pros:
- Never breaks mid-sentence
- Natural reading flow preserved
- Predictable semantic units
Cons:
- Requires NLP dependency for accurate sentence detection
- Short sentences create tiny chunks; long sentences create huge ones
- Doesn’t consider paragraph or section boundaries
Best for: Well-written prose, articles, books, documentation
4. Semantic Chunking
The most sophisticated approach: use embeddings to find natural breakpoints where the topic shifts.
How it works:
- Split into sentences
- Embed each sentence
- Compute similarity between consecutive sentences
- Split where similarity drops below threshold (topic change detected)
Pros:
- Chunks are semantically coherent
- Adapts to content structure dynamically
- Topic changes become chunk boundaries
Cons:
- Computationally expensive (requires embedding every sentence)
- Chunk sizes highly variable
- Threshold tuning required
Best for: Long-form content with multiple topics, research papers, complex documents
The Chunk Size Tradeoff: Too Small vs. Too Large
This is where most practitioners struggle. Let’s break down the tradeoffs:
Too Small (< 200 tokens)
Problems:
- Lost context: “The company was founded in 2015” means nothing without knowing which company
- Fragmented answers: The answer to a question spans multiple chunks, but you only retrieve one
- Embedding noise: Short text has less semantic signal, leading to worse similarity matching
- Retrieval overhead: More chunks = more storage, more comparisons, higher latency
Symptoms: Answers feel incomplete. Users ask follow-ups that should have been covered.
Too Large (> 1000 tokens)
Problems:
- Diluted relevance: The chunk contains the answer plus 20 unrelated paragraphs
- Token budget waste: You blow your context window on irrelevant text
- Lower precision: Many chunks “kind of” match, making ranking harder
- LLM confusion: More context isn’t always better-models can get distracted
Symptoms: Retrieved context feels bloated. LLM outputs mention irrelevant details.
The Sweet Spot
For most use cases, 256–512 tokens hits the balance:

But here’s the real answer: it depends on your data and queries.
- Q&A over technical docs? Smaller chunks (256) work well-answers are often localized
- Summarization of reports? Larger chunks (512–1024) preserve narrative flow
- Legal document search? Semantic chunking-clause boundaries matter more than size
Benchmark Methodology
To produce meaningful comparisons, our benchmark follows these principles:
Corpus Selection
We use the same corpus for all strategies-a technical document on machine learning fundamentals. In production, use a representative sample of your actual documents.
Evaluation Metrics
- Precision: What fraction of retrieved chunks contain relevant information?
- Recall: What fraction of the expected information was retrieved?
- F1 Score: Harmonic mean of precision and recall
Test Protocol
- Chunk the corpus with each strategy × size combination
- Embed and index all chunks using the same embedding model
- Run identical queries against each index
- Retrieve top-k (k=3) chunks per query
- Score against expected keywords
Test Environment
Python Version: 3.11.14Platform: Linux 6.14.0-37-genericProcessor: x86_64CPU Cores: 4 physical, 8 logicalRAM: 15.3 GBSentenceTransformers: 5.2.2ChromaDB: 1.5.0
Variables Controlled
VariableValueEmbedding modelall-MiniLM-L6-v2Vector storeChromaDB (cosine similarity)Top-k3Chunk overlap50 characters
Results and Analysis
Running the benchmark on our ML corpus produces the following results:
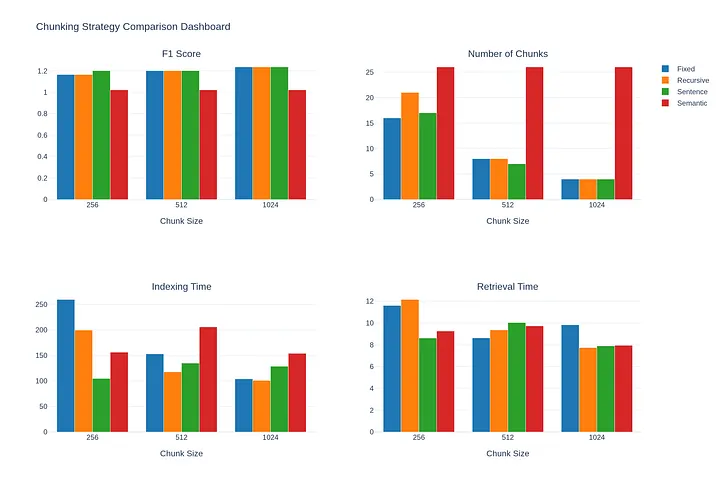
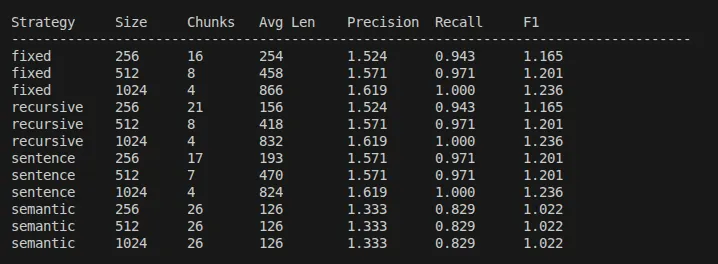
Key Findings
- Larger chunks (1024) achieve the highest F1 score (1.236) across fixed, recursive, and sentence-based strategies, with perfect recall (1.0). This suggests that for this corpus, preserving more context improves retrieval quality.
- Sentence-based chunking offers the best speed-to-quality ratio. At 256 characters, it achieves F1 of 1.201 with fast indexing (104.73ms) and retrieval (8.62ms) times.
- Semantic chunking underperforms contrary to expectations, achieving only F1 of 1.022. The algorithm created many small chunks (avg 125.9 chars) regardless of target size, fragmenting the content too aggressively.
- Recursive chunking is faster than fixed-size with identical quality scores, making it the better default choice. It respects natural boundaries while maintaining performance.
- The 1024 sweet spot emerges for this corpus. All strategies converge to similar performance at 1024 characters, suggesting this size captures complete semantic units.
Performance Considerations
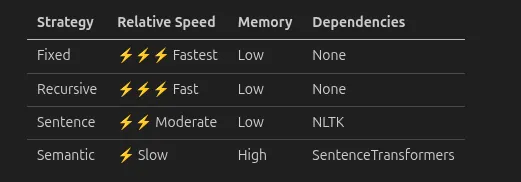
Semantic chunking requires embedding every sentence-on large corpus, which becomes expensive. Consider batch processing or using a faster embedding model.
Practical Recommendations by Use Case
📚 Technical Documentation / Knowledge Bases
- Strategy: Recursive or Sentence-based
- Chunk size: 256–512 tokens
- Why: Answers are typically contained in single sections. Smaller chunks = higher precision.
📄 Legal Documents / Contracts
- Strategy: Semantic or custom section-aware
- Chunk size: 512–768 tokens
- Why: Clause boundaries matter. Semantic chunking detects topic shifts.
💬 Customer Support / FAQ
- Strategy: Sentence-based
- Chunk size: 128–256 tokens
- Why: Q&A pairs are short. Smaller chunks prevent mixing unrelated questions.
📖 Books / Long-form Content
- Strategy: Semantic with larger thresholds
- Chunk size: 512–1024 tokens
- Why: Narrative flow matters. Larger chunks preserve context.
📊 Structured Data (Tables, Lists)
- Strategy: Custom structure-aware splitting
- Chunk size: Keep logical units intact
- Why: Standard splitters mangle tables. Build custom logic to keep rows/items together.
🔬 Research Papers
- Strategy: Section-aware + semantic
- Chunk size: 512 tokens within sections
- Why: Papers have a clear structure (Abstract, Methods, Results). Chunk within sections.
Conclusion
Chunking is not a solved problem-it’s a tuning problem. The optimal strategy depends on:
- Your document types — Structured vs. unstructured, short vs. long
- Your query patterns — Factoid questions vs. exploratory search
- Your constraints — Latency requirements, embedding costs, token budgets
Start here:
- Use RecursiveCharacterTextSplitter at 512 characters with 50 character overlap
- Benchmark with your actual documents and queries
- If precision matters more, try smaller chunks or semantic chunking
- If context matters more, try larger chunks or sentence-based
The code in this post gives you everything needed to run your own experiments. Clone it, swap in your corpus, and find your optimal configuration.
Remember: A 10% improvement in chunking can translate to a dramatically better user experience. It’s worth the investment to get it right.
Code Repository: All benchmark code and examples are available at github.com/Devparihar5/chunking-strategies-comparison
References
- LangChain Text Splitters Documentation:
- ChromaDB Documentation:
- Sentence Transformers:
- “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks” — Lewis et al., 2020
- “Lost in the Middle: How Language Models Use Long Contexts” — Liu et al., 2023
- NLTK Tokenization:
Have questions or want to share your chunking results? Feel free to reach out or open an issue in the repository.







