Giving LLMs a Brain: Building a Long-Term Memory System with Python, LangChain, and FAISS

Published on

Have you ever had a deep, meaningful conversation with an AI, only to come back the next day and find it has forgotten everything about you? It’s the “50 First Dates” problem of modern AI. While Large Language Models (LLMs) are incredibly smart, they suffer from a severe case of amnesia. Once the context window closes, the memory is gone.
In this post, I’ll walk you through how I built a Long-Term Memory System for LLM agents that allows them to extract, store, and recall personalized information across conversations. We’ll use LangChain, OpenAI, FAISS for vector search, and SQLite for persistent storage.
The Problem: Context Window vs. Long-Term Memory
LLMs have a “context window”, a limited amount of text they can process at once. You can stuff user history into this window, but it gets expensive and eventually runs out of space. Plus, it’s inefficient to re-read the entire history of every conversation just to know the user’s name or favorite programming language.
We need a system that acts like a human brain:
- Short-term memory: The current conversation.
- Long-term memory: Important facts stored away and retrieved only when relevant.
The Solution: RAG + Semantic Search
We’re building a specialized Retrieval-Augmented Generation (RAG) pipeline. Instead of retrieving generic documents, we are retrieving personal memories about the user.
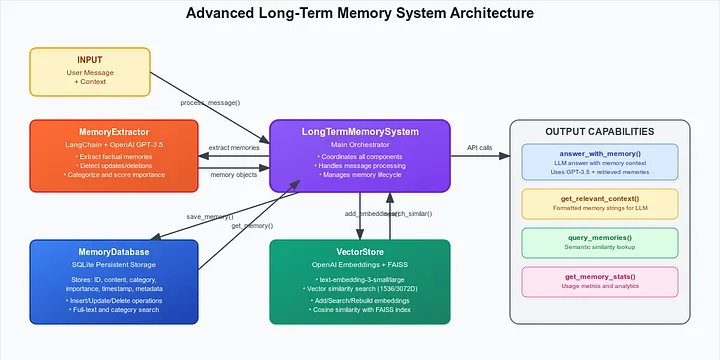
Key Components
- Memory Extractor: An LLM agent that “listens” to the chat and identifies facts worth saving.
- Vector Store (FAISS): Stores the “meaning” (embedding) of the memory for fuzzy search.
- SQL Database: Stores the structured data (content, timestamp, category) for reliability.
- Retrieval System: Fetches relevant memories based on the current user query.
Step 1: Defining a Memory
First, we need a structure. A memory isn’t just text; it has metadata.
from dataclasses import dataclass
from typing import List, Dict, Optional
@dataclass
class Memory:
id: str
content: str
category: str # e.g., 'tools', 'personal', 'work'
importance: float # 0.0 to 1.0
timestamp: str
embedding: Optional[List[float]] = None
metadata: Optional[Dict] = None
Step 2: Extracting Memories with LangChain
We don’t want to save everything. “Hello” is not a memory. “I use VS Code for Python development” is.
We use LangChain and a carefully crafted system prompt to extract structured data.
# memory_system.py (Simplified)
prompt = ChatPromptTemplate.from_messages([
("system", """You are an expert at extracting factual information.
Focus on preferences, tools, personal info, habits.
Return a list of memories with an importance score (0-1).
"""),
("human", "Message: {message}")
])
# Output is structured JSON
# User: "I mostly code in Python but use Rust for side projects."
# Result: [
# {"content": "Codes primarily in Python", "category": "skills", "importance": 0.9},
# {"content": "Uses Rust for side projects", "category": "skills", "importance": 0.7}
# ]
Step 3: The “Brain” (Vector Store + Database)
We use a hybrid storage approach.
Why FAISS? We need to answer questions like “What tools do I use?” even if the memory is recorded as “I work with NeoVim.” Keyword search fails here, but Vector Search understands that NeoVim is a tool.
Why SQLite? Vectors are great for search but bad for reading. We need a reliable place to store the actual text, timestamps, and IDs to handle updates and deletions.
class VectorStore:
def __init__(self, openai_api_key):
self.embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
self.index = faiss.IndexFlatIP(1536) # Inner Product for Cosine Similarity
def add_memory(self, text):
vector = self.embeddings.embed_query(text)
self.index.add(np.array([vector]))
Step 4: Connecting the Dots
The main loop handles the flow:
- User sends message.
- System extracts facts (if any).
- System checks for updates (Did the user say “Actually, I switched to Java”?).
- System retrieves relevant history based on the current message.
- LLM generates response using the retrieved memories as context.
def answer_with_memory(self, question):
# 1. Search vector DB for similar memories
relevant_memories = self.vector_store.search_similar(question)
# 2. Construct context
context = "\n".join([m.content for m in relevant_memories])
# 3. Ask LLM
prompt = f"Based on these memories:\n{context}\n\nAnswer: {question}"
return self.llm.invoke(prompt)
The Interface
I built a Streamlit app to visualize this “brain”. You can see the memories forming in real-time, search through them, and even see how the system categorizes your life.
You can access the live demo from https://llm-long-term-memory.streamlit.app/.
Why This Matters
This isn’t just about remembering names. It’s about Personalization.
- A coding assistant that remembers your preferred libraries.
- A tutor that remembers what you struggled with last week.
- A therapist bot that remembers your long-term goals.
Future Improvements
- Graph Database: Linking memories (e.g., “Paris” is related to “France”).
- Local LLMs: Running Llama 3 for privacy.
- Time Decay: Slowly “forgetting” unimportant memories over time.
Check out the Code
The full code is available on GitHub. It includes the complete detailed implementation of the memory extractor, vector store management, and the Streamlit UI.
Thanks for reading! Let me know in the comments how you handle state in your LLM apps.







